cmd输出日志如何带时间戳 | 每秒千万级实时数据处理系统的设计与存储服务
一、cmd输出日志如何带时间戳
在命令提示符(cmd)或脚本执行过程中,为输出日志添加时间戳是监控、调试和审计的关键操作。以下是几种常见方法:
1. 使用PowerShell命令
PowerShell内置了时间戳功能。例如,执行命令并添加时间戳:`powershell
PowerShell "Get-Date -Format 'yyyy-MM-dd HH:mm:ss'; <你的命令>"`
或者使用管道:`powershell
<你的命令> | ForEach-Object { "$(Get-Date -Format 'yyyy-MM-dd HH:mm:ss') $_" }`
2. 在批处理脚本中使用变量
在Windows批处理文件(.bat或.cmd)中,可通过%time%和%date%变量:`batch
echo [%date% %time%] 日志内容`
3. 使用Linux/macOS的Bash
在类Unix系统中,常用date命令:`bash
echo "$(date '+%Y-%m-%d %H:%M:%S') 日志内容"`
4. 编程语言集成
如Python、Java等程序可在代码中直接生成带时间戳的日志,推荐使用标准库(如Python的logging模块)。
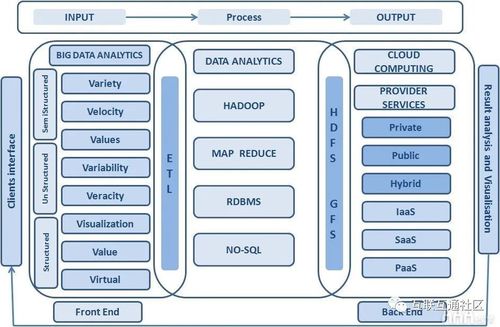
二、每秒千万级实时数据处理系统设计
处理每秒千万级数据的实时系统需兼顾高吞吐、低延迟和容错性。以下是核心设计要点:
1. 架构分层
- 数据采集层:使用分布式日志收集器(如Apache Kafka、Flume)缓冲数据,避免数据源过载。
- 流处理层:采用流处理框架(如Apache Flink、Apache Storm、Spark Streaming)进行实时计算,支持窗口操作和状态管理。
- 存储层:根据查询需求选择存储系统(如时序数据库、列存储或内存数据库)。
- 服务层:提供API供下游应用调用处理结果。
2. 关键技术
- 水平扩展:通过分区(如Kafka Topic分区)和分布式计算节点分摊负载。
- 内存优化:使用堆外内存、序列化框架(如Apache Avro)减少GC压力。
- 异步与非阻塞I/O:提升网络与磁盘吞吐量。
- 容错与一致性:通过检查点(Checkpoint)和事件时间处理保证Exactly-Once语义。
3. 监控与运维
- 实时监控系统指标(如延迟、吞吐量),使用Prometheus和Grafana。
- 自动化部署和扩缩容(如Kubernetes)。
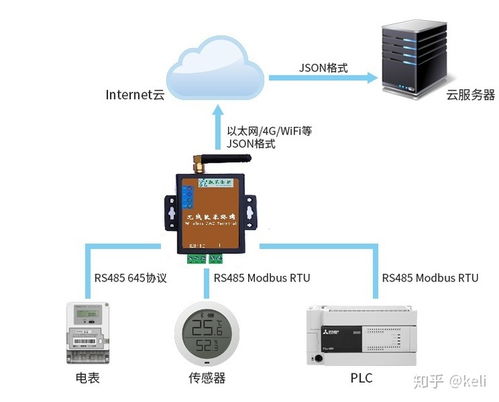
三、数据处理存储服务
存储服务需根据数据特性(如热/冷数据、查询模式)选择:
1. 实时数据存储
- 时序数据库:如InfluxDB、TimescaleDB,适合时间序列数据的高效写入与聚合查询。
- 内存数据库:如Redis、Apache Ignite,提供亚毫秒级延迟,用于缓存或实时指标。
- 列式存储:如Apache Cassandra、HBase,支持高并发写入和快速范围查询。
2. 批处理与数据湖
- 使用云存储(如AWS S3、Azure Blob)或HDFS存放原始数据,配合Presto、Apache Hive进行交互查询。
3. 数据服务化
- 通过REST API或gRPC暴露数据访问接口,结合缓存(如CDN、Redis)降低后端压力。
4. 数据治理
- 实施数据生命周期管理(自动归档、删除),保障合规性与成本控制。
##
从cmd日志时间戳的简单操作,到每秒千万级实时处理系统的复杂架构,再到数据存储服务的多样化选择,技术方案需紧密结合业务场景。实时系统的成功依赖于分层设计、合适的技术栈以及持续的监控优化,而存储服务则需平衡性能、成本与可维护性。随着云计算和开源生态的发展,构建高性能数据处理系统已变得更加可行和高效。
如若转载,请注明出处:http://www.wzewkaew.com/product/15.html
更新时间:2026-06-18 23:58:31